A faire
Rédaction article
Relire intro St Clair
S’inspirer structure pour mon intro
Trouver biblio intro
Rédiger l’intro
Regarder les applications pour les collections de réseaux recommender system
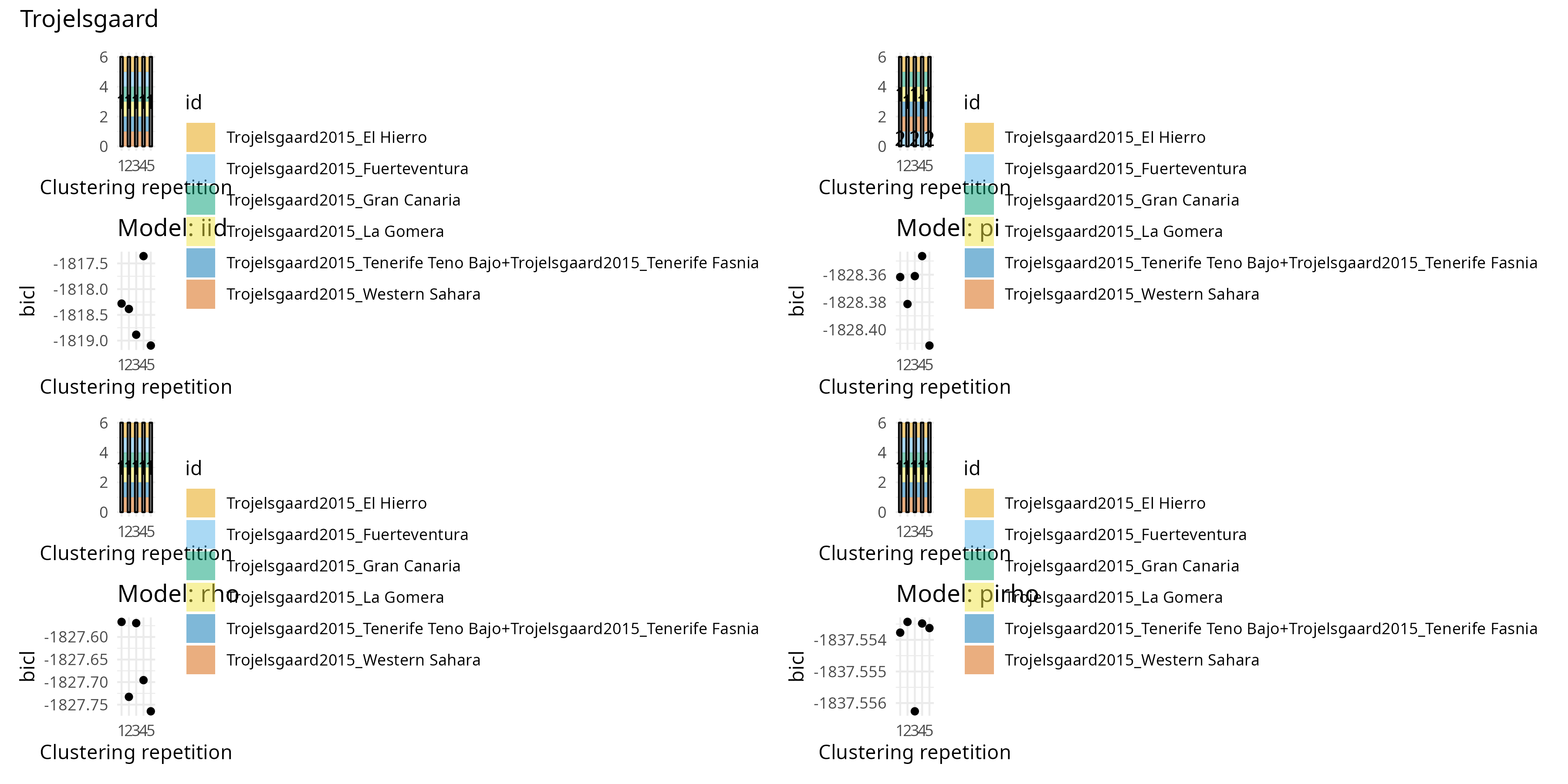
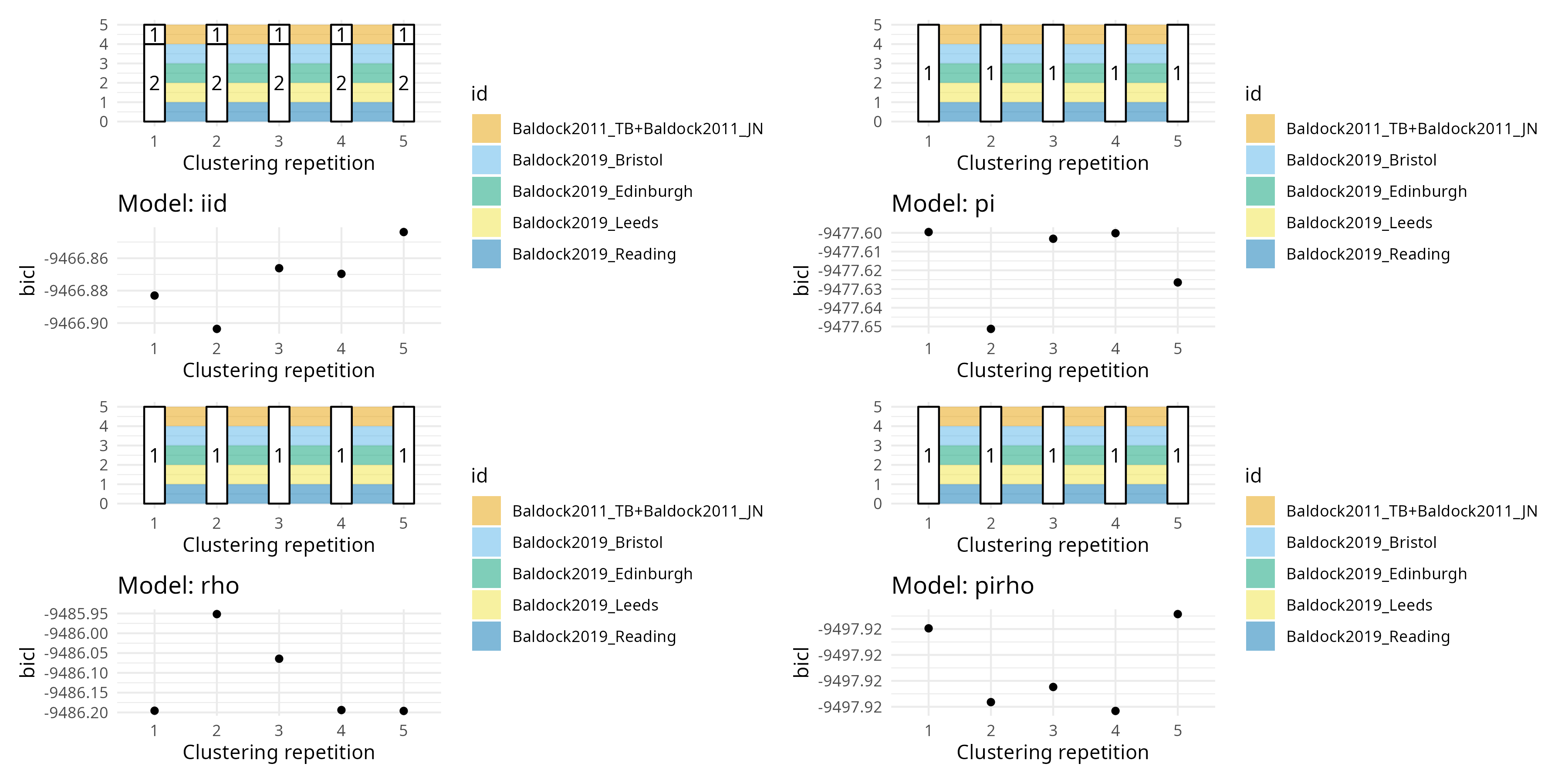
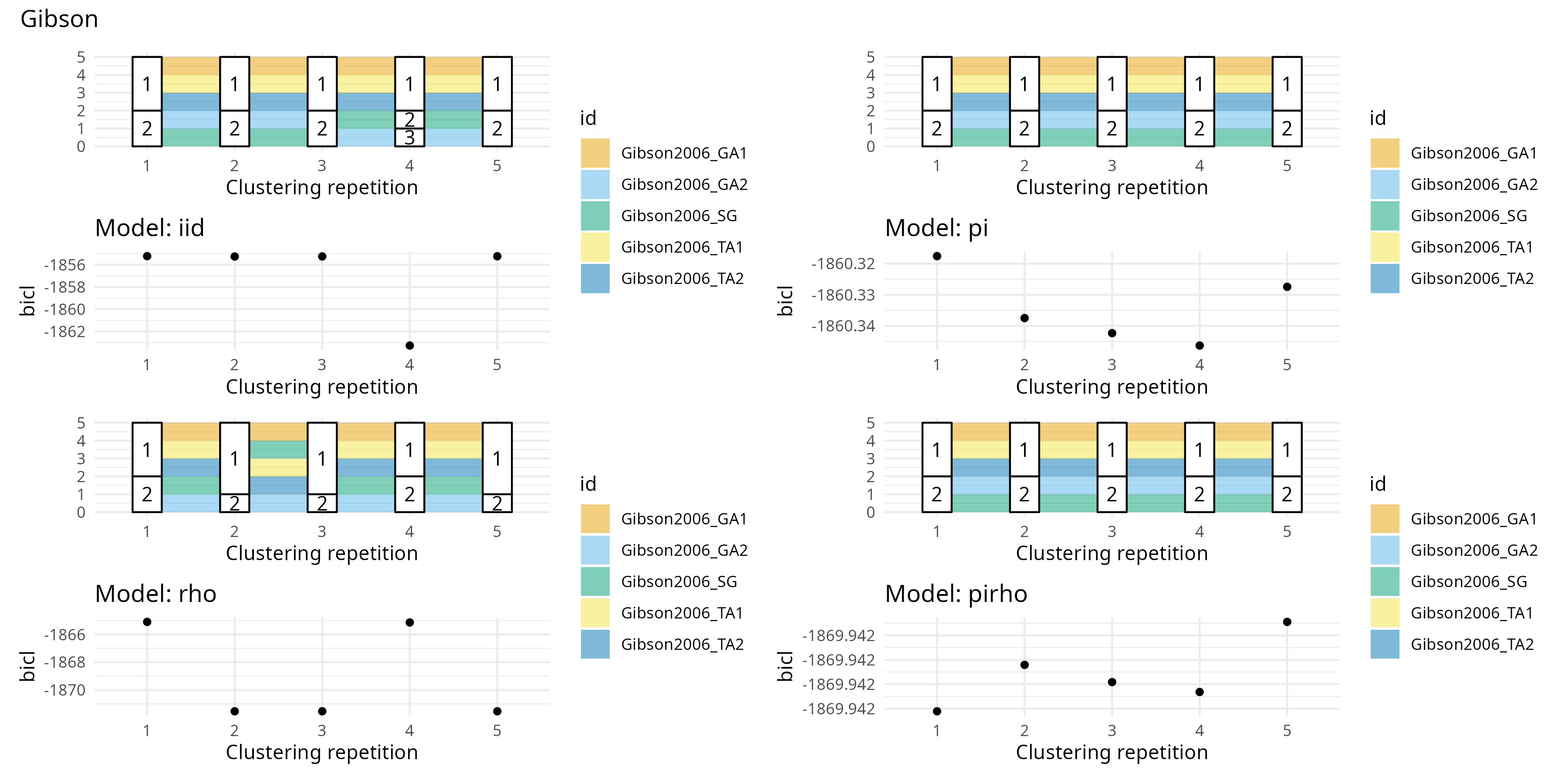
Lire les papiers de Baldock Traveset Souza Cordeniz Trojelsgaard et Gibson
Dire résultats nettement meilleurs et variabilités inférieures.
Simulations article
Relancer simus clustering avec VEM steps = 10 000 et plus nombreux init pour spectral
Ajouter simu clustering métriques nb sous-collections obtenues. Vérifier les résultats obtenus si ARI = 0. Et augmenter la taille M = 30 avec M_1 = M_2 = M_3 = 10.
Comparer sur clustering unipartite avec versions symétriser des par blocs des matrices d’adjacences.
Corriger structure de simus :
- Pour noisy \alpha :
- Logit pour envoyer la gaussienne vers (0,1)
- Beta contrainte dans (0,1)
- Pour noisy links : Générer
nb_clusteringcollections de taille M puis prélever \epsilon_{max}n_r n_c liens à inverser puis pour les \epsilon < \epsilon_{max} prélever dans la liste des indices afin d’avoir des perturbations emboitées.
- Pour noisy \alpha :
Applications
- Kmeans sur la densité des réseaux subdoré pour pré-partitionner et clusteriser.
Autour de l’article et du package
- Créer des vignettes illustrant par exemple des cas de simulations. Possible de mettre l’exemple d’application de Sophie sur les réseaux avec gradient d’urbanisation.
J’ai fait
Créer un README descriptif du dépôt des codes pour l’article.
Remonter figure sélection de modèle dans le corps de l’article
Enrichir légende de la figure 7 et 8
Supprimer p_NA des autres cadrans des proportions de NA
Basculer le code du clustering pour utiliser hclust et mis l’argument method de hclust avec single par défaut
Ajouter pipeline qui knit README.Rmd à chaque merge dans main colSBM
A continuer
Résultats simus NA Erreur pour certaines conditions : Pour NA robustness générer
nb_repcollections de taille M=2 et prélever \epsilon_{max}n_r n_c liens à retirer puis pour les \epsilon < \epsilon_{max} prélever dans la liste des indices afin d’avoir des perturbations emboitées. Il faut que j’ajoute un mécanisme pour reprendre des conditions qui ont plantés et que je skip dans le future_lapply les conditions déjà traitées (pour avoir la même seed quand je vais exécuter le code). Implémenté les missing steps en attente des résultats MIGALE.Lire Biological Networks - François Képès
J’ai esquissé des bouts d’intro
Relancer simus d’inférence avec n = 240 pour voir si la qualité augmenter (se rassurer). En fait on est déjà à 240, j’ai relancé avec M = 4 au lieu de M = 2. En attente résultats MIGALE
Correction méthodo
Idée Pierre : Regarder la contribution au BICL de la collection des réseaux et comparer au sep BICL pour essayer de repérer les outliers. En regardant la vbound (pas la pénalité) de chaque réseau dans le joint vs sa vbound dans le sep -> Résultats : pas de différences majeures entre les réseaux avec le rapport vbound_joint/vbound_sep, les outliers ne sont pas marqués.
Regarder si plutôt que k médioid possible meilleurs résultats avec d’autres distances hclust avec min, max etc… -> L’algo PAM donne des clusters équilibrés sans séparer les outliers Je regarde avec plutôt des hclust avec métrique single pour séparer les outliers.
Voir si in fine possible de repérer des outliers à partir de ces nouvelles métriques
Regarder la répartition de densité dans les réseaux sub-doré -> déséquilibrée
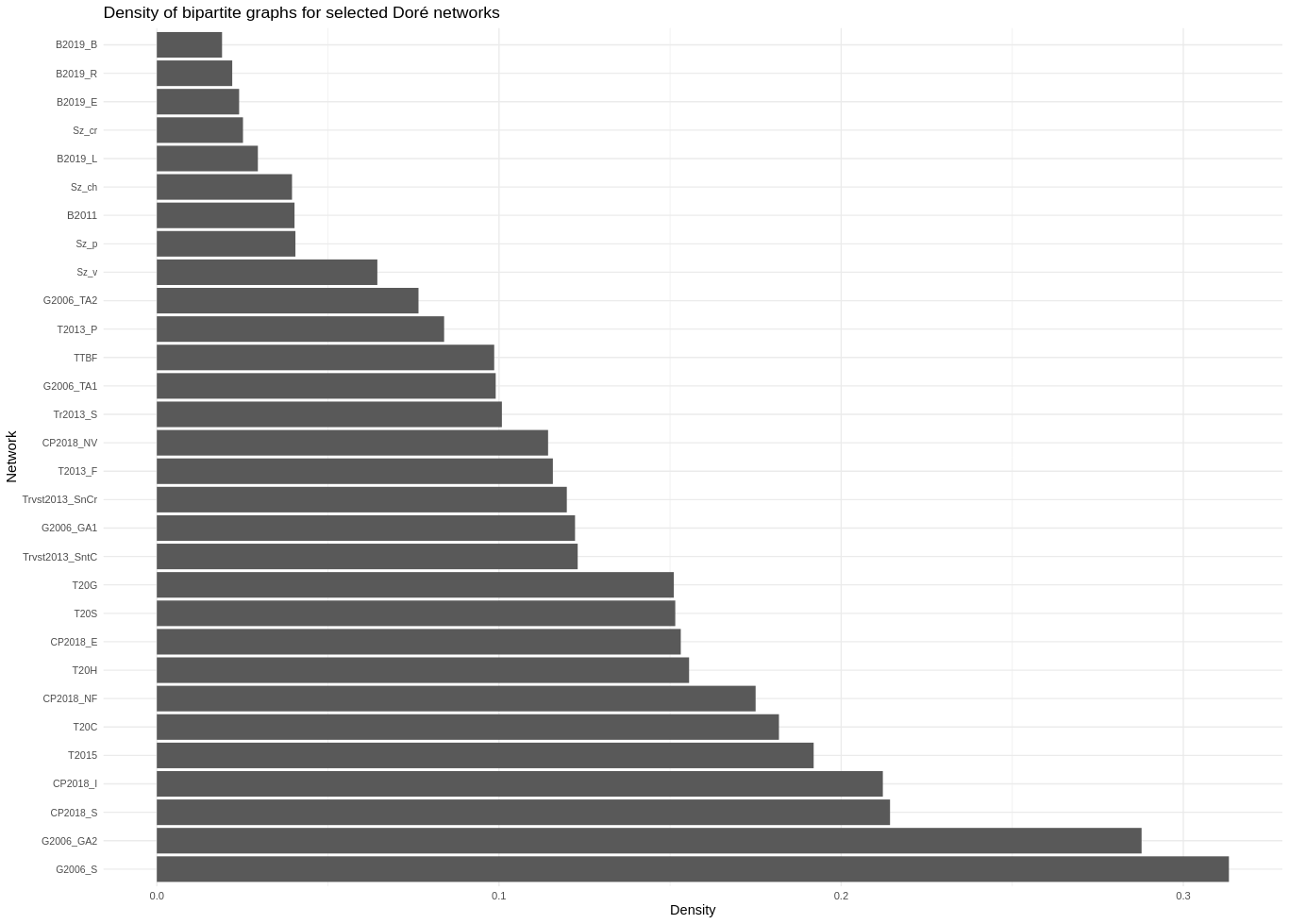
En faisant des clusterings par densité on constate qu'avec un modèle iid pour des réseaux dont la densité est entre :
- 0 et 0.05 : Baldock et Souza tout le monde se retrouvait ensemble avec *Partitioning around medoids*Applications
- Idée Sophie: Regarder clustering de données plantes-pollinisateur selon gradient d’urbanisation
Sophie a fait une appli qui marche bien et va dans le sens de l’analyse faite (à savoir pas d’effet du gradien d’urbanisation). À continuer pour l’intégrer dans l’article !
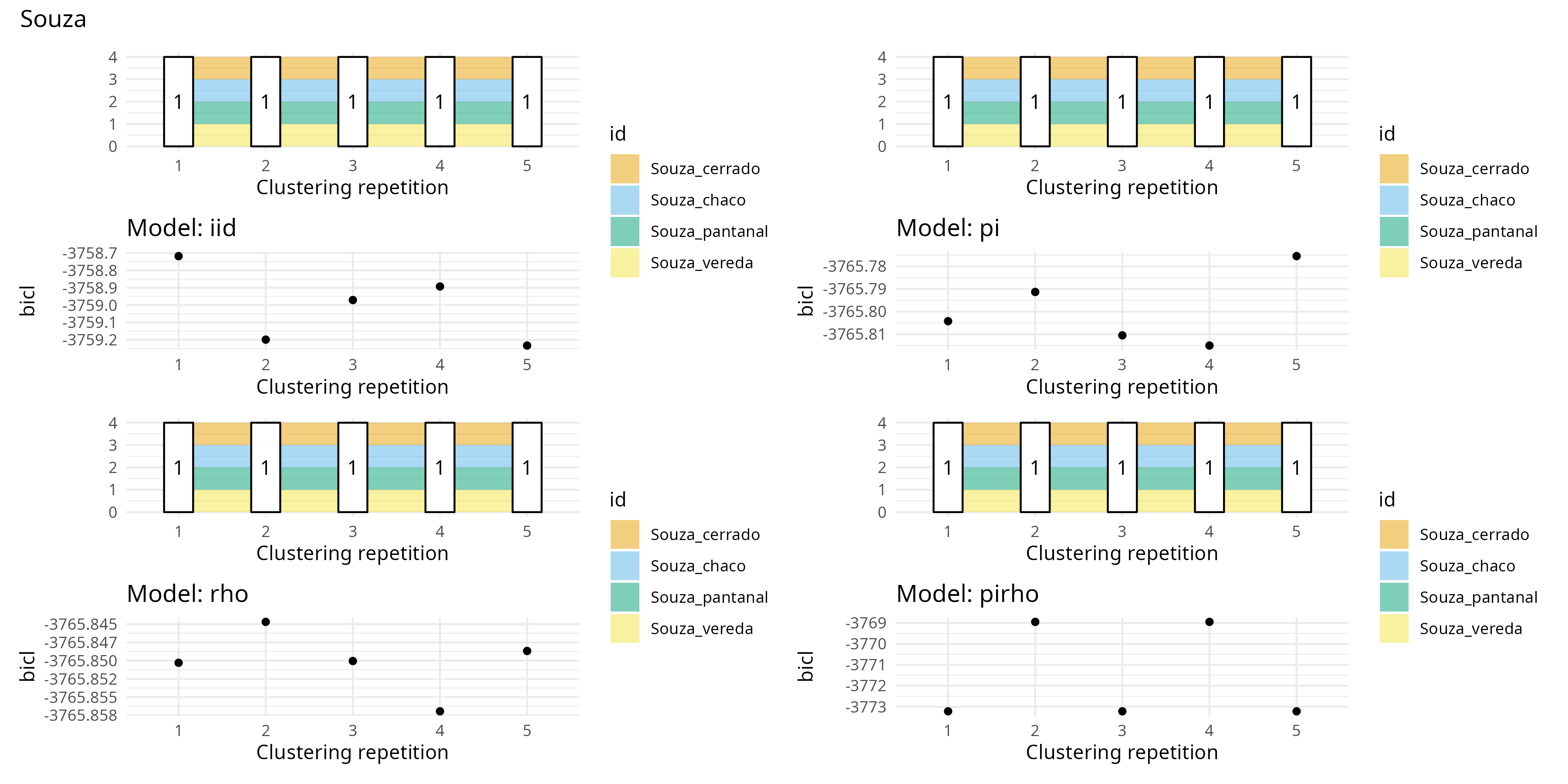
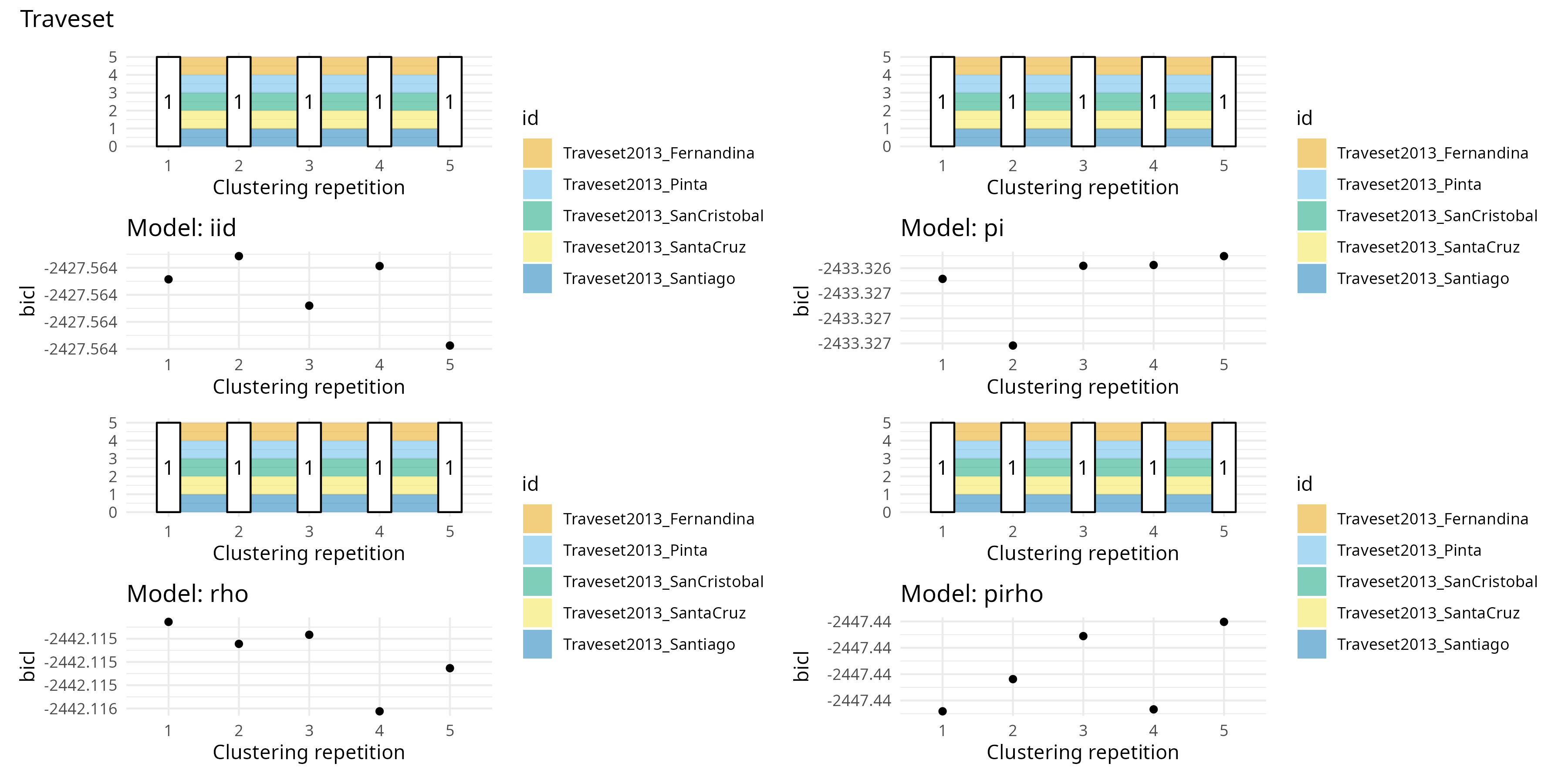
Lancer clustering auteur par auteur du sub-Doré : 5 collections différentes dans l’idée.
Une fois fait, Sophie ne trouve pas que ce soit le plus pertinent pour illustrer le clustering. Plus intéressant de garder le clustering de données simulées (M = 30) et se servir des exemples dessous et des parcours exhaustif des possibilités de partitionnement comme comparatif.
Baldock
Gibson
Souza
Traveset
Trojelsgaard