
TODO List
- ✅ Préparer la séance intro à Git pour le 13 juin. La séance s’est très bien passée
- Pour clustering de collections sur données réelles :
→ L’intuition de Pierre semble être confirmé, les dissimilarités semblent arrêter de varier sensiblement pour de grandes valeurs (Q_1,Q_2).- Faire le
hclustavec diverses distances et voir si les coupes proposées diffèrent sensiblement - Si plusieurs clustering possibles les tester et sélectionner le meilleur
- Ré-ajuster les bonnes partitions.
- ✅ C’est bon j’ai une fonction qui tourne, mais lentement ⌛
- ⏳Simulations en train de tourner
- ❗L’approche que j’ai en mettant la pénalité à 0 peut favoriser de séparer trop les réseaux et donc il faudrait refusionner. ➡️ mais le d&a ne fonctionne qu’en iid
- Faire le
- ✅ Idée de Sophie : alterner descendant et ascendant → prometteur aussi. J’ai codé le fichier de simulations et débugguer le vecteur de clustering ▶️ à voir les performances. ➡️ la simu à 9 réseaux (bcp de variabilité a priori) est lancée attente résultats ➡️ Je tombe sur un bug déjà rencontré dans les simus d’inférence. j’ai lancé sans parallélisation pour essayer de comprendre le bug.
✅ Il y avait un bug dans la fenêtre glissant où la condition d’arrêt quand le BICL n’augmentait plus était mal détectée. Corrigé

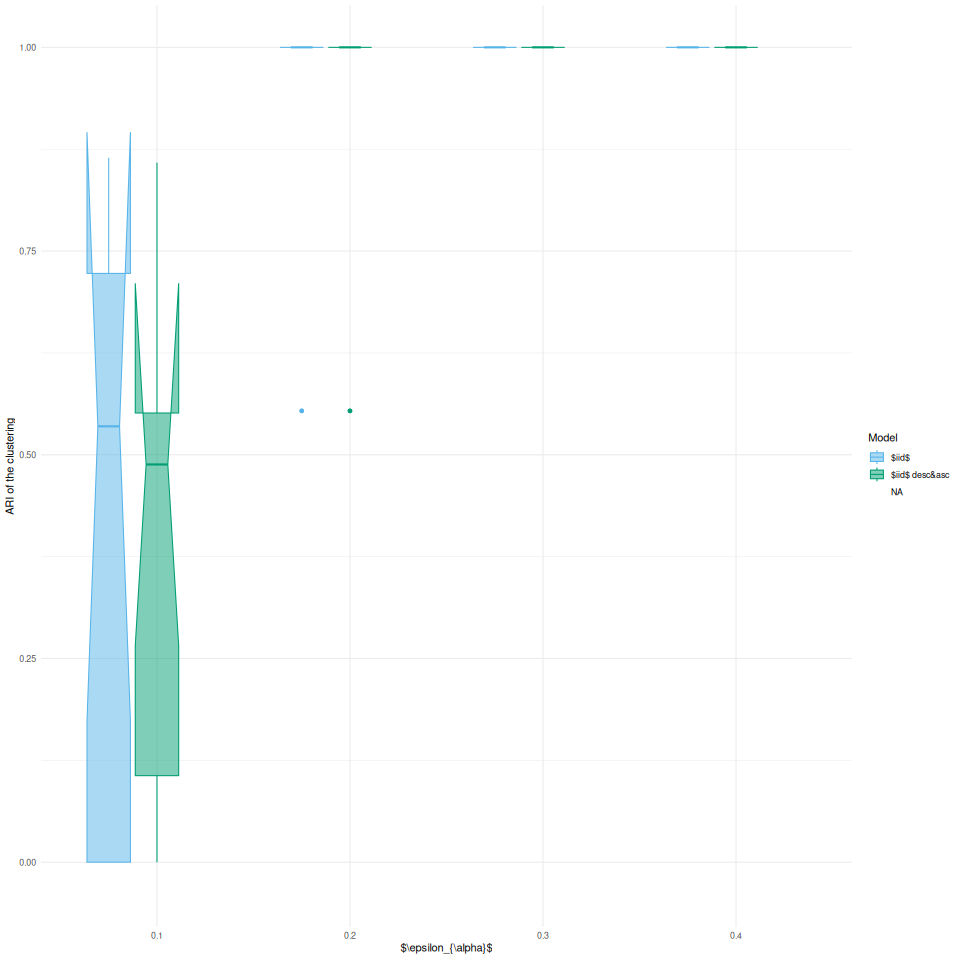
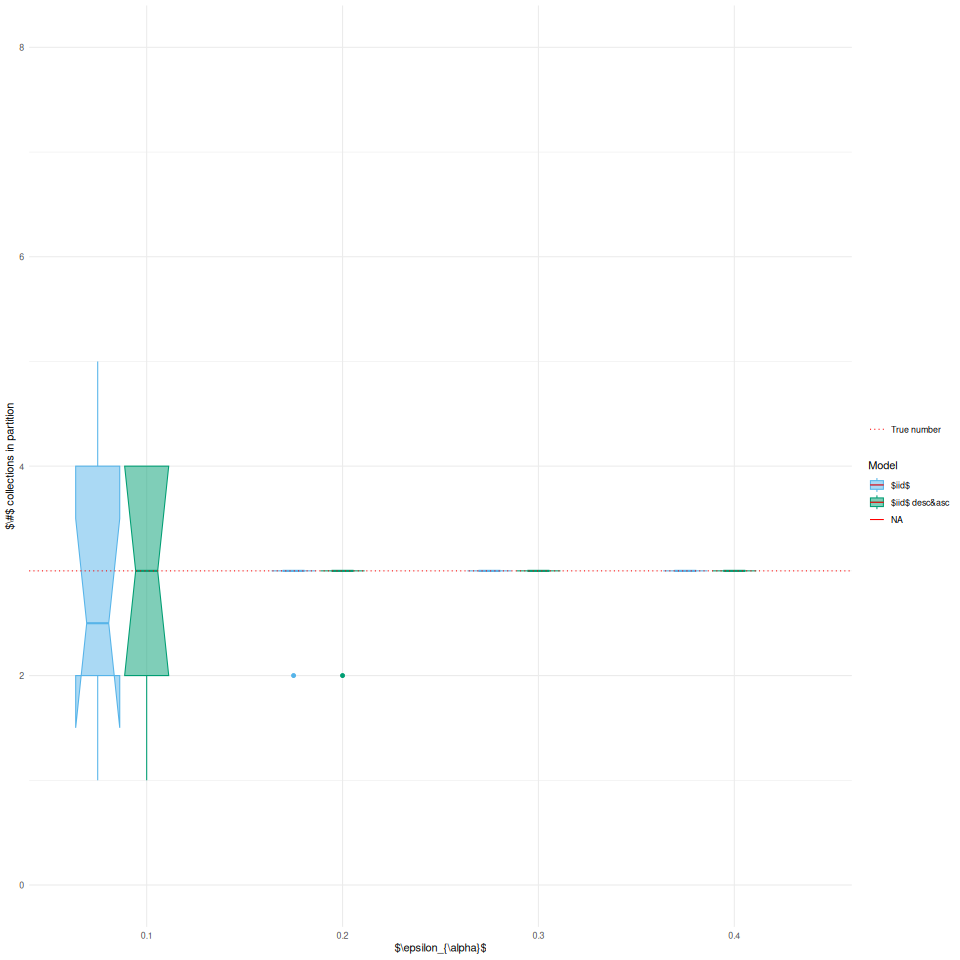
Pour les deux propositions données simulées tester diverses distances.
Dé-bugger les simulations :
- Inférence : Relancer simus d’inférence avec n = 240 pour voir si la qualité augmenter (se rassurer). En fait on est déjà à 240, j’ai relancé avec M = 4 au lieu de M = 2. En attente résultats MIGALE -> BUG, dois creuser mais juste des problèmes techniques -> Visiblement il y a d’autres problèmes que juste le plan de parallélisation.
Vérifier si problème de version tidyverse pour vapply sur l’inférence.
Si problème de parallélisation vient de pb de version future.callr le signaler à MIGALE.
✅ Réparé mauvais placement des légendes, des valeurs etc.
Applications
- Kmeans sur la densité des réseaux subdoré pour pré-partitionner et clusteriser. Car densités déséquilibrées.
- Faire GNN-VAE Doré et sub-Doré avec kmeans et clustering sur l’espace latent J’ai commencé à regarder un peu
- Comparer les perfs du VAE sur Baldock avec colBiSBM par exemple
Inférence et microbes
- Lancer colBiSBM sur OTU\times Sample → problème du chargement en mémoire des données à voir
- Se renseigner techniques d’inférence de réseaux :
- covariance (base corrélation et seuil)
- GraphicalLASSO
- Co-occurence
- Lancer colSBM sur OTU\times OTU
- Creuser TabNet de Christophe Regouby et les exercices
- Regarder SPARTA Rennes
- Lire Papiers compositional data (Aitchison et al. intro)
- Lire article multi-niveaux Saint-Clair
- Demander à JA si elle connaît des réseaux d’interactions connus par les experts (idée d’intégrer une connaissance experte et de voir les différences de structure par rapport à celle attendue)
- Ecrire et étudier les modèles pour différents niveaux taxonomiques. \begin{align*} i \rightarrow &~N^1_i \subseteq N^2_i \subseteq N^3_i & \text{Taxonomie}\\ Z^0_i \overset{?}{=} & Z^1_i \overset{?}{=} Z^2_i \overset{?}{=} Z^3_i & \text{Groupes fonctionnels} \end{align*}
Lecture en cours
OT
A discuter
Inférence
- Papier pour comprendre données
Faust et al.- Abdill et al.
- Bashan et al.
- pbs : variance, bcp de zero, covariables, offset et taxonomie (Reseaux arretes differents niveaux : Genre, OTU …)
Combine networks at different taxonomic levels
- Inférence + GREMLINS
Rédaction article
- Relire intro St Clair
- S’inspirer structure pour mon intro
- Trouver biblio intro
- Rédiger l’intro
- Dire résultats nettement meilleurs et variabilités inférieures.
A continuer
Applications
- Idée Sophie: Regarder clustering de données plantes-pollinisateur selon gradient d’urbanisation
Sophie a fait une appli qui marche bien et va dans le sens de l’analyse faite (à savoir pas d’effet du gradien d’urbanisation). À continuer pour l’intégrer dans l’article !
Axe inférence
- Lire biblio fournie Julie, Inférence de réseaux : co-occurence
J’ai lu Faust et al. Je lis Abdill et al.
Repoussés ou abandonnés
- Résultats simus NA Erreur pour certaines conditions : Pour NA robustness générer
nb_repcollections de taille M=2 et prélever \epsilon_{max}n_r n_c liens à retirer puis pour les \epsilon < \epsilon_{max} prélever dans la liste des indices afin d’avoir des perturbations emboitées. Il faut que j’ajoute un mécanisme pour reprendre des conditions qui ont plantés et que je skip dans le future_lapply les conditions déjà traitées (pour avoir la même seed quand je vais exécuter le code). Implémenté les missing steps.
Je n’arrive pas à comprendre les erreurs qui arrivent
Lire Biological Networks - François Képès
Regarder les applications pour les collections de réseaux recommender system Pas pertinents et trop gros
Par exemple :
Papier plus multi-applications
- Données d’Elisa herbivore ?
- Données urbanisations ?
Autour de l’article et du package
- Créer des vignettes illustrant par exemple des cas de simulations. Possible de mettre l’exemple d’application de Sophie sur les réseaux avec gradient d’urbanisation.
Simulations article
Comparer sur clustering unipartite avec versions symétriser des par blocs des matrices d’adjacences.
Corriger structure de simus :
- Pour noisy \alpha :
- Logit pour envoyer la gaussienne vers (0,1)
- Beta contrainte dans (0,1)
- Pour noisy links : Générer
nb_clusteringcollections de taille M puis prélever \epsilon_{max}n_r n_c liens à inverser puis pour les \epsilon < \epsilon_{max} prélever dans la liste des indices afin d’avoir des perturbations emboitées.
- Pour noisy \alpha :